Master Vision-Language-Action for Autonomous Driving
Build a real autonomous driving system from scratch. Learn vision encoders, transformers, CLIP, and train a VLA model that drives a TurboPi robot using only a camera.Hardware not included — purchase separately. Simulation alternative available.
Want to try first? Access free lecture videos →
Dr. Sreedath Panat
MIT PhD · Founder, Vizuara
Alumni of
Hear from Dr. Sreedath Panat
Why VLA Matters Now
The autonomous driving industry is undergoing its biggest architectural shift since deep learning.
The End-to-End Revolution
VLAs collapse 5+ separate modules into a single trainable model. Tesla, Waymo, and every major AV lab is pivoting to end-to-end approaches.
Language = Reasoning Power
VLAs don't just see, they reason. Language grounding enables handling edge cases, passenger instructions, and unseen scenarios.
The Skills Gap is Now
Waymo, Cruise, Tesla FSD, and Mobileye are hiring ML engineers with VLA expertise. This bootcamp puts you at the frontier.

Multi-class object detection: the perception backbone a VLA must master
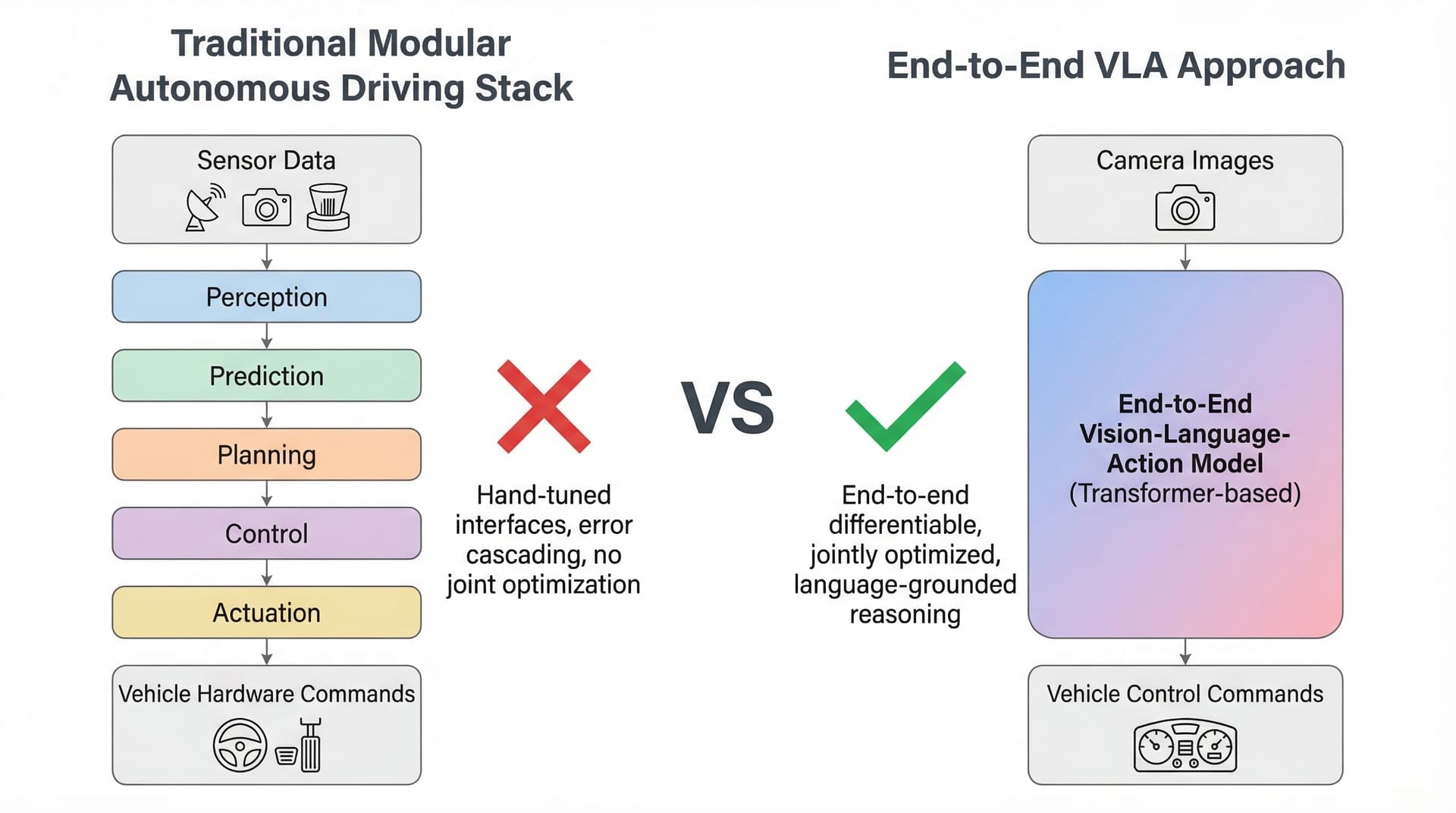
Traditional modular stack vs. end-to-end VLA model
What is a VLA Model?
Vision-Language-Action models unify perception, reasoning, and control into a single neural network that can drive a car.
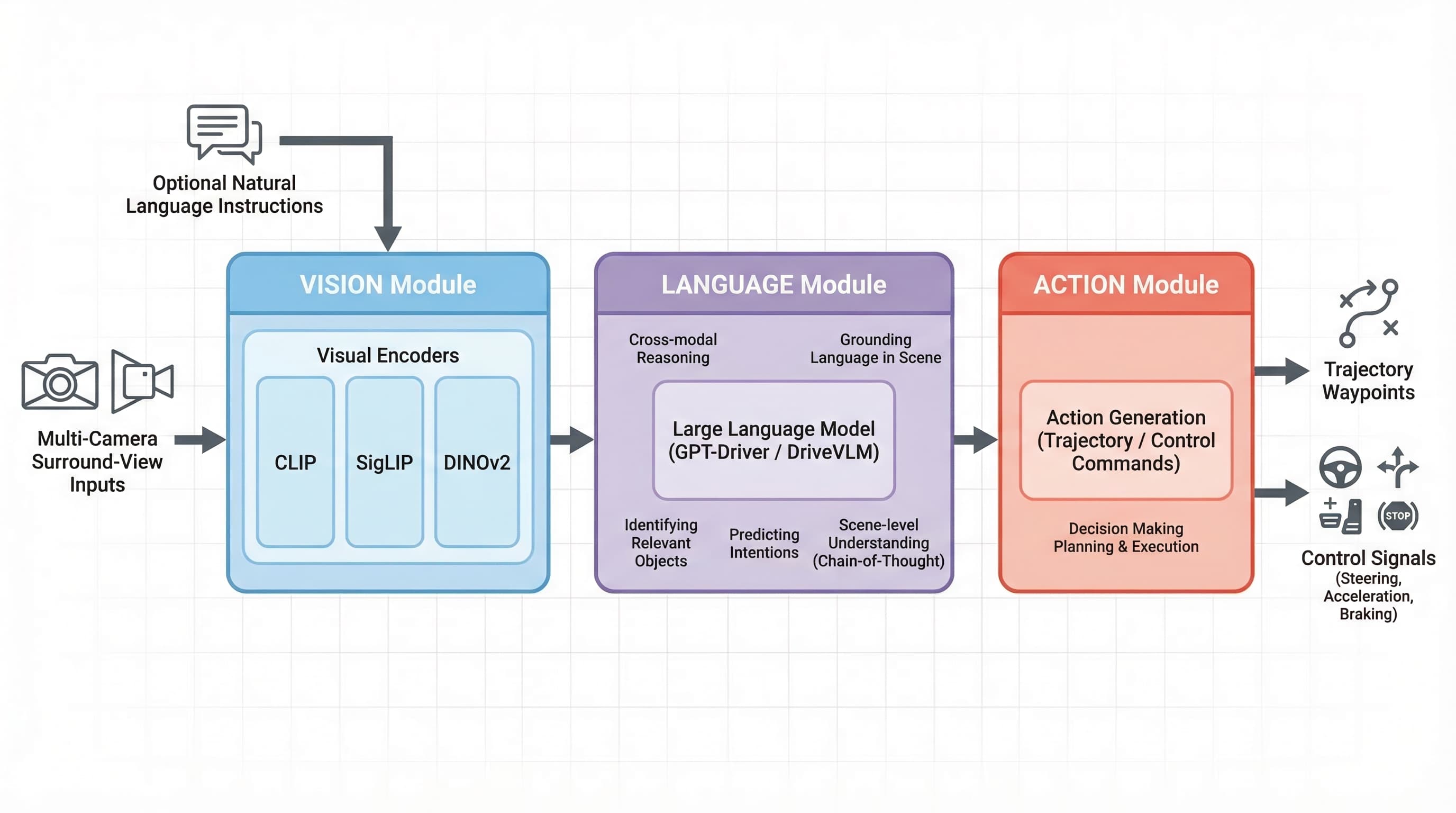
End-to-end VLA pipeline: multi-camera inputs are encoded by vision transformers, processed by a language model for scene reasoning, and decoded into vehicle control signals
Visual encoders (CLIP, SigLIP, DINOv2) tokenize camera feeds into rich representations: lane geometry, traffic signs, pedestrians, and dynamic objects.
Language reasoning enables understanding traffic context, interpreting commands, and explaining decisions. Models like GPT-Driver ground language in driving scenes.
The action head outputs steering angles, acceleration values, and waypoint trajectories for direct vehicle control.
Multi-sensor 3D perception: LiDAR point clouds with object detection across driving scenarios
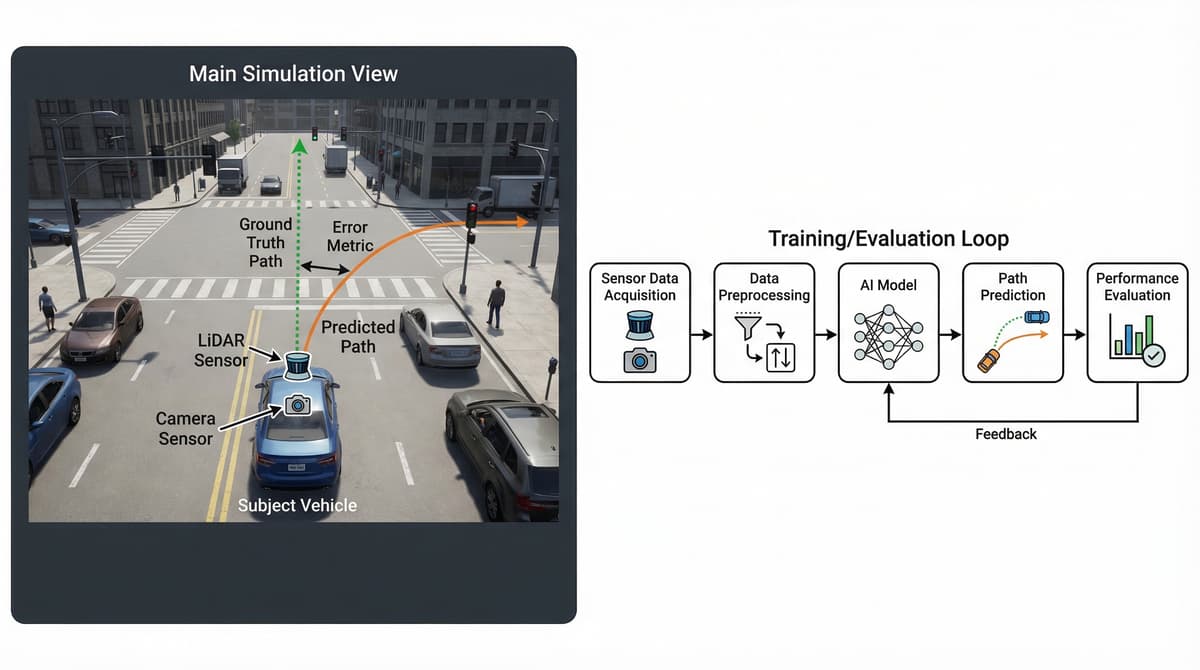
Train and evaluate VLA models in simulation before hardware deployment
Inside a VLA Architecture
Camera Input
Multi-view RGB
Vision Encoder
ViT / CLIP / DINOv2
Language Model
LLM Backbone
Action Head
ACT / Diffusion Policy
Why VLA is a Paradigm Shift
End-to-End Differentiable
The entire pipeline is trainable with no hand-tuned interfaces.
Language Grounding
Generalizes to novel scenarios through natural language reasoning.
Data Scalability
Performance scales with data: more driving data means better decisions.
Explainability
Decisions can be explained in natural language, aiding debugging and safety.
Is This Bootcamp Right for You?
Whether you're an ML engineer, researcher, or grad student: if you want to build the future of autonomous driving, this is your accelerator.
ML Engineers
Transitioning to Autonomous Vehicles
You have PyTorch experience and want to specialize in the fastest-growing domain in AI: autonomous driving with VLA models.
Computer Vision Researchers
Exploring Embodied AI
You work with CLIP, ViT, or similar vision models and want to extend into embodied AI where vision drives physical actions.
Robotics & AV Engineers
Replacing the Modular Stack
You work with ROS or CARLA and want to transition from hand-tuned pipelines to end-to-end learned models.
PhD Students
Pursuing Publication-Quality Research
You're researching vision, language, or robotics and want thesis-ready expertise in VLA: the intersection of all three.
Prerequisites: Basic Python proficiency, familiarity with NumPy/Matplotlib, and some exposure to machine learning concepts. No prior autonomous vehicle or hardware experience required.
Meet Your Robot: TurboPi
In Part 2 of the bootcamp, you deploy your VLA model on a real HiWonder TurboPi robot car.

HiWonder TurboPi
A Raspberry Pi-powered robot car with mecanum wheels for omnidirectional movement and an HD camera for vision. Your VLA model will process camera frames and output motor commands to drive this robot autonomously.
Raspberry Pi 4B
Quad-core ARM Cortex-A72
480P HD Camera
2-DOF pan-tilt mount
Mecanum Wheels
360° omnidirectional motion
WiFi Control
Remote access via VNC
Hardware not included. You will need to purchase the TurboPi yourself. Details and setup instructions at hiwonder.com.
No Hardware? No Problem.
If you don't have access to TurboPi hardware, all Part 2 exercises include a simulation alternative. You'll work with virtual environments and simulated sensor data so you can complete the full curriculum and build your VLA model regardless of hardware availability.
What You'll Learn
From foundations to real hardware. Each 90-minute session includes hands-on exercises.
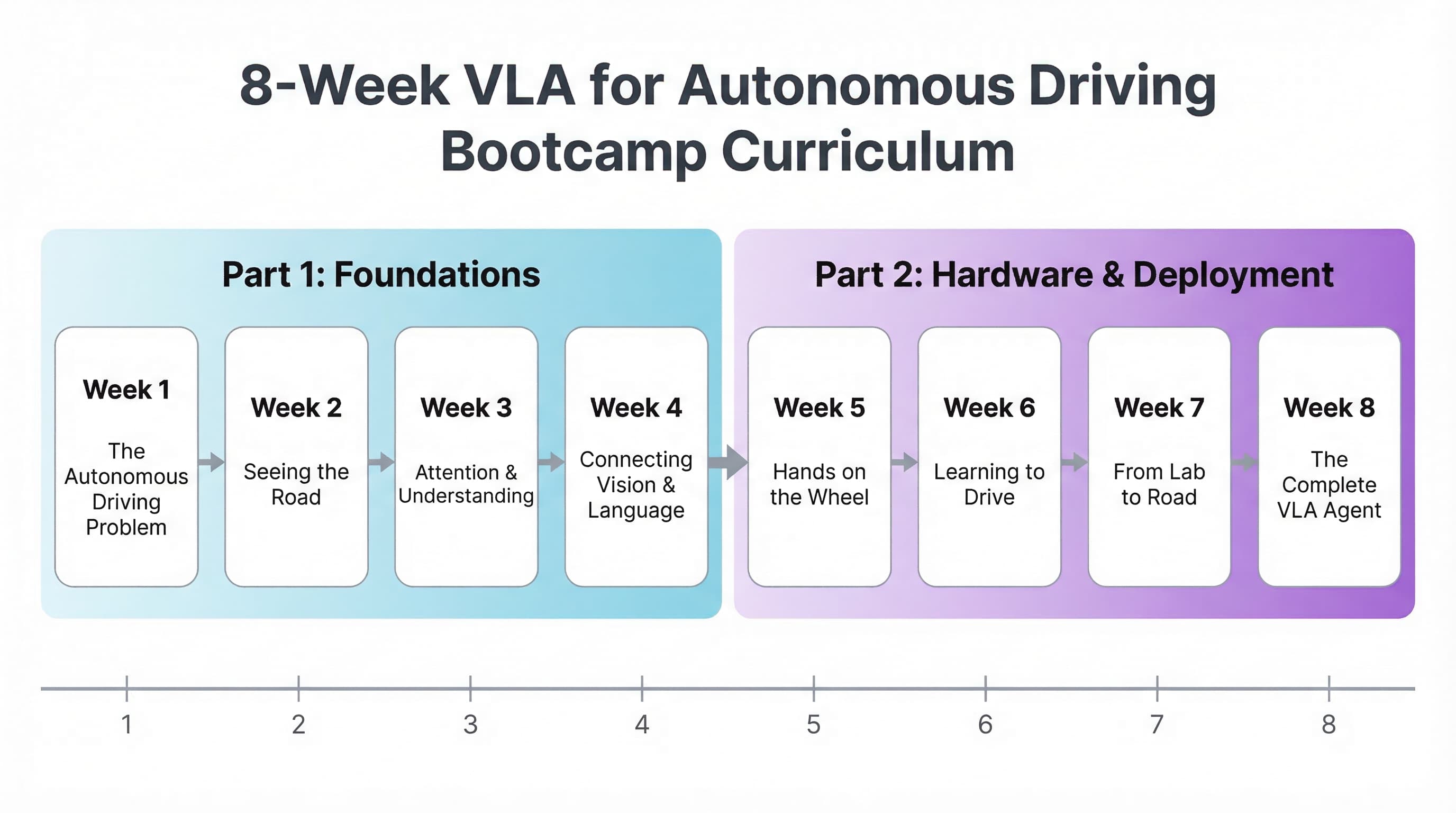
8 weeks across 2 parts: from vision and language foundations to autonomous driving on real hardware
Vision, Language & Driving Perception. Work with public driving datasets and standard ML tools.
Introduction to VLA & The Autonomous Driving Problem
- ●Perception, planning, control pipeline
- ●Modular vs. end-to-end learning
- ●VLA evolution
- ●Dataset exploration (nuScenes, BDD100K)
Hands-on: Set up environment and build a basic CNN driving classifier
Computer Vision for Driving
- ●CNNs and hierarchical feature extraction
- ●ResNet-18 with skip connections
- ●Driving image preprocessing
- ●CNN feature map visualization
Hands-on: Train a driving scene classifier
Vision Transformers & Attention
- ●Self-attention from scratch
- ●ViT: patch embedding, positional encoding
- ●Attention map visualization
- ●ResNet vs. ViT comparison
Hands-on: Implement self-attention and build a minimal ViT
Language Meets Driving: CLIP & VLMs
- ●CLIP contrastive learning
- ●Zero-shot scene classification
- ●VLM architecture
- ●Connecting to the VLA concept
Hands-on: Zero-shot classification with CLIP and mini VLM inference
TurboPi hardware, imitation learning, ACT policy, and full VLA deployment.
TurboPi Setup & Imitation Learning
- ●TurboPi hardware control
- ●Mecanum wheel programming
- ●Live camera with ResNet/ViT/CLIP
- ●Behavior cloning fundamentals
Hands-on: Control TurboPi and collect driving demonstrations
Data Collection & ACT Architecture
- ●Dataset quality evaluation
- ●ACT: vision backbone + transformer encoder/decoder
- ●CVAE for multi-modal behavior
- ●Adapting ACT for TurboPi
Hands-on: Implement ACT dataset class and verify forward pass
Training, Evaluation & Deployment
- ●Training ACT with proper hyperparameters
- ●Loss curves and qualitative inspection
- ●Offline trajectory evaluation
- ●Real-time deployment on TurboPi
Hands-on: Train, evaluate, deploy, and iterate
Full VLA: Language-Conditioned Driving
- ●Language conditioning with CLIP embeddings
- ●Instructions modifying driving behavior
- ●Training a language-conditioned policy
- ●State-of-the-art VLA and future directions
Hands-on: Build and present a language-conditioned VLA agent
Everything Included
Beyond live sessions: a complete toolkit to launch your autonomous driving AI career.
Session Recordings
Lifetime access to all 8 session recordings with chapter markers.
PyTorch Code Repository
Complete code for every session: VLA models, training scripts, evaluation.
Pre-Trained VLA Checkpoints
Skip slow training: experiment immediately with ready-to-use model weights.
TurboPi Hardware Project
Complete autonomous driving project on real TurboPi robot with Raspberry Pi 4 and camera.
Lecture Notes & Materials
Hand-written notes, architecture diagrams, and comprehensive PDF booklets.
Discord Community
Private access to peers, instructors, and industry practitioners.
Completion Certificate
Verifiable certificate of completion from Vizuara AI Labs.
Career Acceleration
Industry mentorship, curated job leads at top AV companies, and portfolio-ready capstone.
Meet Your Instructor
Learn from Dr. Sreedath Panat:MIT PhD, computer vision expert, and co-founder of Vizuara AI Labs.

Dr. Sreedath Panat
Lead Instructor · All 8 Sessions
MIT PhD, Computer Vision & ML Expert
Expertise & Experience
Specializations
Teaching Experience
Dr. Panat has successfully taught computer vision and deep learning courses to 500+ students globally, with a 4.9/5 rating. His hands-on approach ensures every concept translates directly to production-ready skills.
Published Author
Co-author of Manning's #1 bestseller “Build a DeepSeek Model (From Scratch)” :demonstrating deep expertise in building large-scale AI models from the ground up.
Build Your Portfolio
Projects from this bootcamp can be hosted on your GitHub and added to your resume, showcasing hands-on experience with VLA models and autonomous driving systems.
What Our Students Say
Hear from engineers, researchers, and students who've learned with Vizuara.
“This bootcamp was one of the most complete and intuition-building journeys I've taken in modern vision: starting from the CNN to transformer transition, then going deep into attention/embeddings, and all the way to ViTs/Swin, detection & segmentation (DETR/Mask2Former/SAM), VLMs (CLIP/BLIP/Flamingo), and multimodal LLMs. Huge credit to Sreedath Panat - rare combo of research-grade depth + crystal-clear teaching. The long-form, "code-along like a real class" style made the ideas stick.”
Research-grade depth + crystal-clear teaching
Sri Aditya Deevi
Robotics + CV Researcher, Aerospace/Field Robotics
“Transformers for Vision was by far the longest and most rewarding bootcamp I have ever taken. One of the biggest highlights for me was going from just reading about transformers to actually implementing them from scratch. That hands-on process gave me insights I could never get from theory alone. The course didn't just show what works, it explained why it works. It was both challenging and genuinely fun.”
From reading papers to implementing from scratch
Koti Reddy
Software Developer
“I thoroughly enjoyed this course and found it extremely valuable. I've always appreciated Sreedath's teaching style, he has a great ability to break down complex concepts into simple, easy to understand explanations. The hands on coding sessions that followed the theory were particularly helpful in strengthening my understanding and applying the concepts practically. Diving into Vision Transformers turned out to be a great decision, and this course exceeded my expectations.”
Complex concepts made simple & practical
Lalatendu Sahu
AI Professional
From our YouTube community
“Thanks for the course this channel is the one stop solution for my all AI topics”
One-stop solution for AI learning
@Aniya Smith
Student
“Honestly, this was the first YouTube video/lecture I watched from start to finish without skipping any part. The trainer and his explanation deserve appreciation.”
Watched completely without skipping
@KensolHomecareProducts
Professional
“This is the best lecture I've seen on different filters in computer vision. Before this, I only knew what these filters were, but I didn't understand the mathematical foundations behind them. The way it's explained is truly impressive.”
Best explanation of mathematical foundations
@SreekanthReddy
Student
Invest in Your AI/ML/CV Career
Choose the plan that fits your learning goals.
Professional
Everything you need to master VLA for autonomous driving.
- Access to all lecture videos
- Miro handwritten notes
- Complete code files
- Compiled PDFs and booklets
- Completion certificate
Researcher
For professionals targeting AI research publication.
- Everything in Professional
- 2 months focused research mentorship
- Research guidance on VLA topics
- Publication support for top venues
- Priority instructor Q&A
Minor in Robotics
VLA bootcamp plus the full Minor in Robotics program.
- VLA for Autonomous Driving (this bootcamp)
- Access to all Minor in Robotics programs
- Comprehensive robotics curriculum
- Significant savings vs. enrolling separately
Frequently Asked Questions
Everything you need to know before enrolling.
Still have questions? Reach out to us
Ready to Build Tomorrow's Autonomous Vehicle AI?
8 sessions. 15+ hours. 100% hands-on. From vision foundations to real hardware deployment. Seats are limited.